Unit 2.4b Using Programs with Data, SQL
Using Programs with Data is focused on SQL and database actions. Part B focuses on learning SQL commands, connections, and curses using an Imperative programming style,




Database Programming is Program with Data
Each Tri 2 Final Project should be an example of a Program with Data.
Prepare to use SQLite in common Imperative Technique
- Explore SQLite Connect object to establish database connection- Explore SQLite Cursor Object to fetch data from a table within a database
Schema of Users table in Sqlite.db
Uses PRAGMA statement to read schema.
Describe Schema, here is resource Resource- What is a database schema?
- What is the purpose of identity Column in SQL database?
- What is the purpose of a primary key in SQL database?
- What are the Data Types in SQL table?
Response
- A schema determines how data is organized in a database.
- The identity column is a column in the table that automatically fills an integer within the column. I'm not certain about this, but the identity column is either related to a column with a primary key or is somehow used to make the primary key.
- A primary key provides a unique number to identify each row.
- The data types are integer, string, and date.
import sqlite3
database = 'instance/sqlite.db' # this is location of database
def schema():
# Connect to the database file
conn = sqlite3.connect(database)
# Create a cursor object to execute SQL queries
cursor = conn.cursor()
# Fetch results of Schema
results = cursor.execute("PRAGMA table_info('users')").fetchall()
# Print the results
for row in results:
print(row)
# Close the database connection
conn.close()
schema()
Reading Users table in Sqlite.db
Uses SQL SELECT statement to read data
- What is a connection object? After you google it, what do you think it does?
- Same for cursor object?
- Look at conn object and cursor object in VSCode debugger. What attributes are in the object?
-
Is "results" an object? How do you know?
Response
-
A connection object establishes a connection between the SQL database and the Python code.
- A cursor object allows execution of SQLite methods.
- One thing I noticed when using the debugger on the conn and cursor object is that they contain function variables. These could be the methods that work with the object. For instance, the function variables of
cursorincludeexecute,executemany, etc., which can also be found here.* No,resultsis a list. Looking at the debugger, you can see thatresultscontains indexes with elements. The elements are the user objects. A quick google search also reports that the.fetchall()method returns table entries in the format of a list.
import sqlite3
def read():
# Connect to the database file
conn = sqlite3.connect(database)
# Create a cursor object to execute SQL queries
cursor = conn.cursor()
# Execute a SELECT statement to retrieve data from a table
results = cursor.execute('SELECT * FROM users').fetchall()
# Print the results
if len(results) == 0:
print("Table is empty")
else:
for row in results:
print(row)
# Close the cursor and connection objects
cursor.close()
conn.close()
read()
Create a new User in table in Sqlite.db
Uses SQL INSERT to add row
- Compore create() in both SQL lessons. What is better or worse in the two implementations?
- Explain purpose of SQL INSERT. Is this the same as User init?
Response
- Both lessons create a user. In 2.4a, the create method contains
db.session.add(object), which adds to the database using SQLAlchemy. However, in 2.4b, sqlite3 is used, which adds entries into the database using sqlite3 commands. The advantages of 2.4a is that the code is easier to read since it is written in Python. The advantages of 2.4b is that OOP is not needed; however, you would need to learn SQL to be able to add entries intot eh database. - INSERT adds a row into the database. It is not the same as
__init__because__init__is a constructor that initializes the variables. However,__init__does not add entries into the database. Thecreate()method does that. On the other hand, INSERT directly adds a row into the database.
import sqlite3
def create():
name = input("Enter your name:")
uid = input("Enter your user id:")
password = input("Enter your password")
dob = input("Enter your date of birth 'YYYY-MM-DD'")
# Connect to the database file
conn = sqlite3.connect(database)
# Create a cursor object to execute SQL commands
cursor = conn.cursor()
try:
# Execute an SQL command to insert data into a table
cursor.execute("INSERT INTO users (_name, _uid, _password, _dob) VALUES (?, ?, ?, ?)", (name, uid, password, dob))
# Commit the changes to the database
conn.commit()
print(f"A new user record {uid} has been created")
except sqlite3.Error as error:
print("Error while executing the INSERT:", error)
# Close the cursor and connection objects
cursor.close()
conn.close()
create()
Updating a User in table in Sqlite.db
Uses SQL UPDATE to modify password
- What does the hacked part do?
- Explain try/except, when would except occur?
- What code seems to be repeated in each of these examples to point, why is it repeated?
- The hacked part checks to see if the password length is too small (1 character). If so, the program will replace the user's inputted password with its own password.
- If there was an error in executing the UPDATE command, an error will be printed onto the terminal.
-
conn = sqlite3.connect(database),cursor = conn.cursor(),cursor.close(), andconn.close()are repeated in each example. They are needed to establish a connection with the database and to perform actions on it.
Side note:Why does UPDATE work but not the update method in 2.4a? >:(
Note: as error takes the error message and stores it in the variable error. This way, you can see what the error is with print(error). It's kind of like import library as name
import sqlite3
def update():
uid = input("Enter user id to update")
password = input("Enter updated password")
if len(password) < 2:
message = "hacked"
password = 'gothackednewpassword123'
else:
message = "successfully updated"
# Connect to the database file
conn = sqlite3.connect(database)
# Create a cursor object to execute SQL commands
cursor = conn.cursor()
try:
# Execute an SQL command to update data in a table
cursor.execute("UPDATE users SET _password = ? WHERE _uid = ?", (password, uid))
if cursor.rowcount == 0:
# The uid was not found in the table
print(f"No uid {uid} was not found in the table")
else:
print(f"The row with user id {uid} the password has been {message}")
conn.commit()
except sqlite3.Error as error:
print("Error while executing the UPDATE:", error)
# Close the cursor and connection objects
cursor.close()
conn.close()
update()
Delete a User in table in Sqlite.db
Uses a delete function to remove a user based on a user input of the id.
- Is DELETE a dangerous operation? Why?
- In the print statemements, what is the "f" and what does {uid} do?
Response
- DELETE can be dangerous because it is unrecoverable.
- The "f" is the format method. This allows easier printing of variables within a string. The variable, in this case,
uid, is put in curly braces so that thestr()typecast is not needed.
import sqlite3
def delete():
uid = input("Enter user id to delete")
# Connect to the database file
conn = sqlite3.connect(database)
# Create a cursor object to execute SQL commands
cursor = conn.cursor()
try:
cursor.execute("DELETE FROM users WHERE _uid = ?", (uid,))
if cursor.rowcount == 0:
# The uid was not found in the table
print(f"No uid {uid} was not found in the table")
else:
# The uid was found in the table and the row was deleted
print(f"The row with uid {uid} was successfully deleted")
conn.commit()
except sqlite3.Error as error:
print("Error while executing the DELETE:", error)
# Close the cursor and connection objects
cursor.close()
conn.close()
delete()
Menu Interface to CRUD operations
CRUD and Schema interactions from one location by running menu. Observe input at the top of VSCode, observe output underneath code cell.
- Why does the menu repeat?
- Could you refactor this menu? Make it work with a List?
Response
- The menu repeats because of a recursive loop (shown at the end of the
menu()function).
def menu():
operation = input("Enter: (C)reate (R)ead (U)pdate or (D)elete or (S)chema")
if operation.lower() == 'c':
create()
elif operation.lower() == 'r':
read()
elif operation.lower() == 'u':
update()
elif operation.lower() == 'd':
delete()
elif operation.lower() == 's':
schema()
elif len(operation)==0: # Escape Key
return
else:
print("Please enter c, r, u, or d")
menu() # recursion, repeat menu
try:
menu() # start menu
except:
print("Perform Jupyter 'Run All' prior to starting menu")
def menu():
operation = input("Enter: (C)reate (R)ead (U)pdate or (D)elete or (S)chema")
operationList = [create, read, update, delete, schema]
option = ["c", "r", "u", "d", "s"]
for i in range(len(option)):
if operation == option[i]:
operationList[i]()
menu() # start menu
Hacks
- Add this Blog to you own Blogging site. In the Blog add notes and observations on each code cell.
- In this implementation, do you see procedural abstraction?
- In 2.4a or 2.4b lecture
- Do you see data abstraction? Complement this with Debugging example.
- Use Imperative or OOP style to Create a new Table or do something that applies to your CPT project.
Reference... sqlite documentation
Response
- Procedural abstraction is present in the form of functions, such as
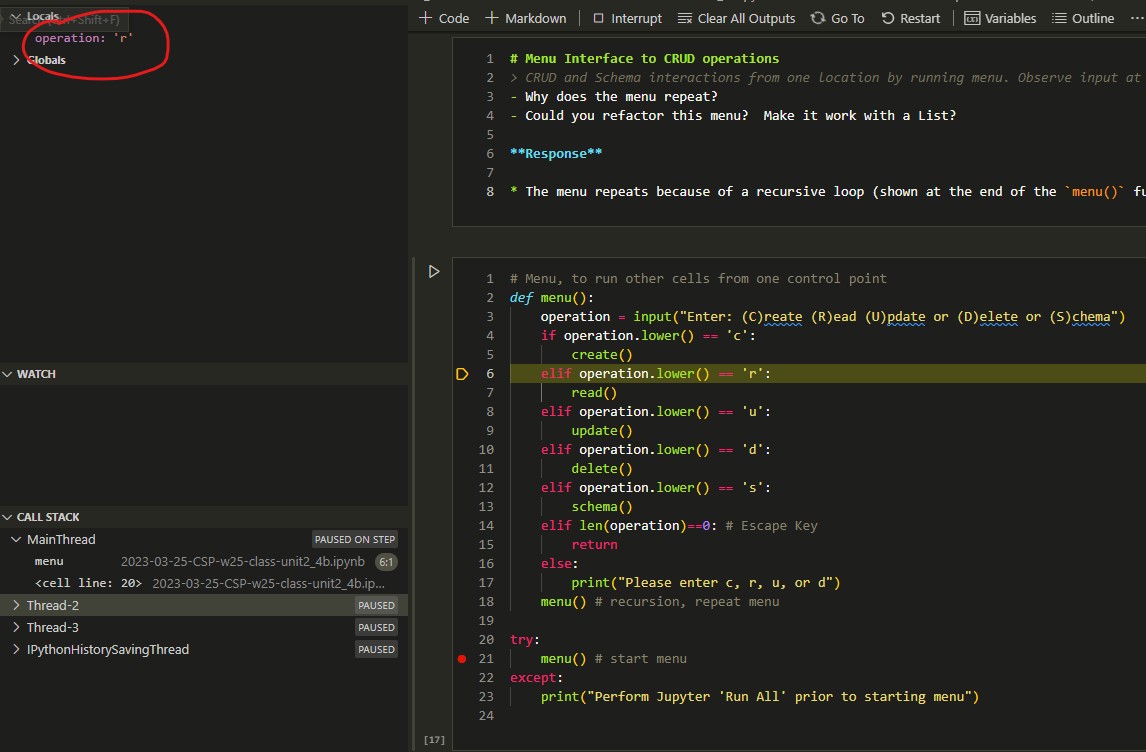
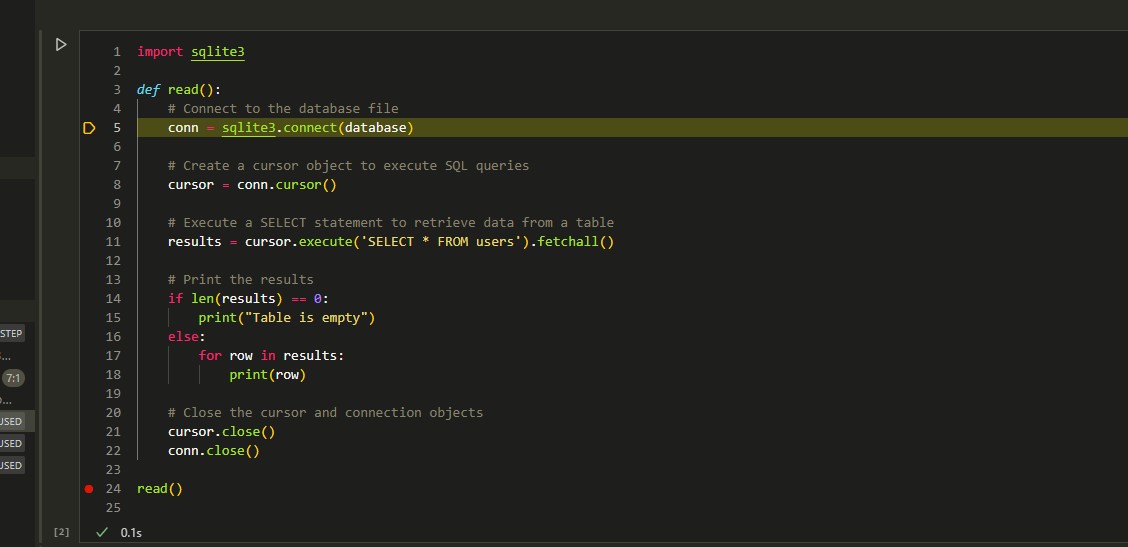
create(),read(), etc. - Data abstraction is shown in the code segment that features the menu. The abstraction uses calls to functions so that the menu function itself looks very clean. Below are pictures of debugging that show calling to a specific function (in this case
read()):
The first picture demonstrates the debugger moving to the if statement that executes the read() function because the user inputted "r".
The second picture shows the debugger moving to the code cell with the read() function.
CPT Work
The thing that I added to my CPT project was an API endpoint that utilized the imperative programming style, which was using the sqlite3 library to write out SQL commands. I did this instead of the OOP method since I already had that in my project.
Below is a picture of what my API endpoint looks like:
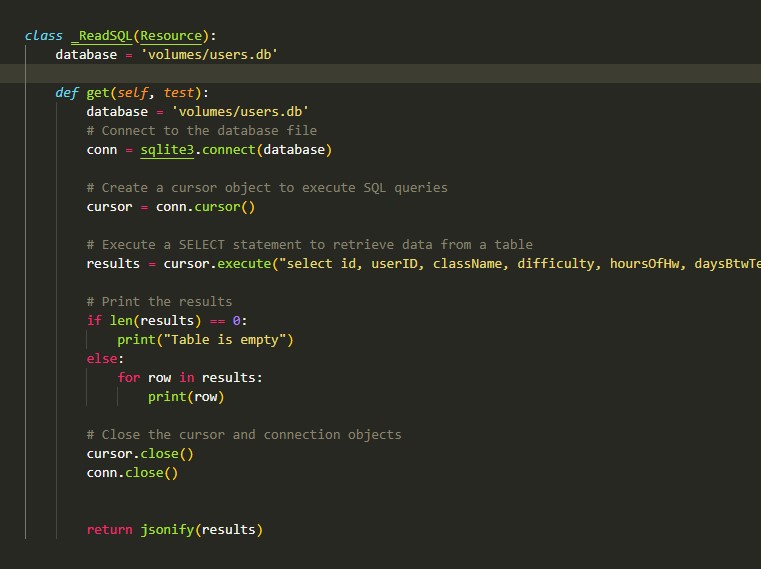
To make the API endpoint, I first added an endpoint at the end of the code with: api.add_resource(_ReadSQL, '/readsql/<test>. <test> takes in a variable in the URL. This took me some time to google, because simply searching something around the lines of api.add_resource add url variables does not give the most helpful results. However, after sifting through some webpages, I found this article, and even on this page, I had to dig really deep until I found the interesting brackets within the URL. I then incorporated it into my Flask Portfolio, took the variable in as a parameter in the get() method, and then used it in my SQL query, which ultimately worked (yay).
The second thing I learned was writing SQL queries. My endpoint takes in a user ID that the user provides and outputs their class reviews. To write this in sqlite3, my code was: select id, userID, className, difficulty, hoursOfHw, daysBtwTest, memorizationLevel, comments from classReview where id = " + test. Let's break this statement down into a few pieces. First, select id, userID... means to output the contents from the column name. from classReview specifies which table to query, and where id =... retrieves the specific row where the id matches the specified keywords. In this case, the keyword is the value of test, which is specified in the API endpoint as a variable in the URL.
What I also learned was that to add Python variables into a SQL statement, add a plus sign behind the SQL command (which is in quotes which means that the command is a string) and then add the variable name. This is similar to concatenating strings with variables.