Project
Songs
Overview
The music recommender utilizes item-item collaborative filtering within collaborative based filtering. In other words, the program analyzes the music that users like. It then calculates a similarity score and populates it into a cooccurence matrix. The highest scores are obtained from the matrix, and the songs that they are associated with are the recommended songs.
Introduction
To make the music recommender, there are two types of recommendation systems. The first is content based filtering, and the second is collaborative based filtering. The music recommender uses collaborative based filtering.
Collaborative based filtering consists of two parts:
- Item-Item collaborative filtering
- User item collaborative filtering
The music recommender uses item-item collaborative filtering. Item-item collaborative filtering will find items that a user liked based on other items that they like. In other words, it is “Users who liked this item also liked…”
Next, a cooccurrence matrix is created. What is a cooccurrence matrix? These are matrices found in item-item filtering. An example is this:
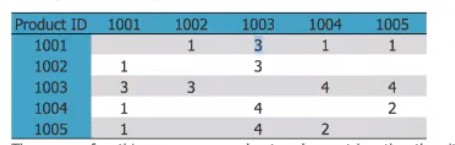
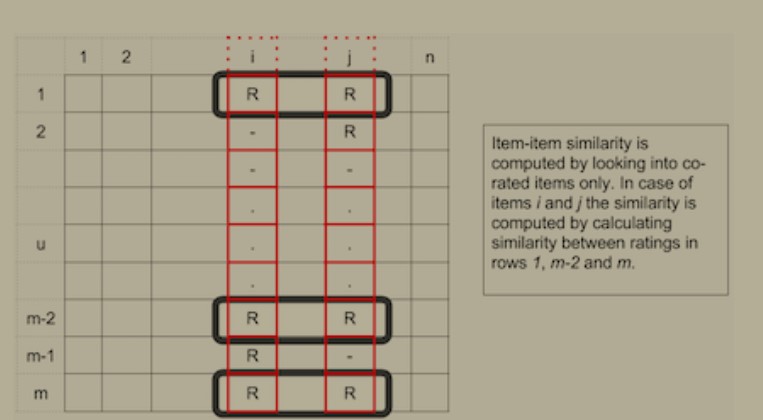
Afterwards, we want to calculate the similarity. What is similarity? Going back to item-item collaborative filtering, it requires a user-item matrix to be created. In this case, the user is the user, while the item is the song. After a user-item matrix is created, the similarity can be calculated to create a similarity matrix.
In item-item filtering, the similarity includes 2 items, and many users (whereas in user-item filtering, the similarity includes 2 users, and many items).
Looks something like this:
Reflection
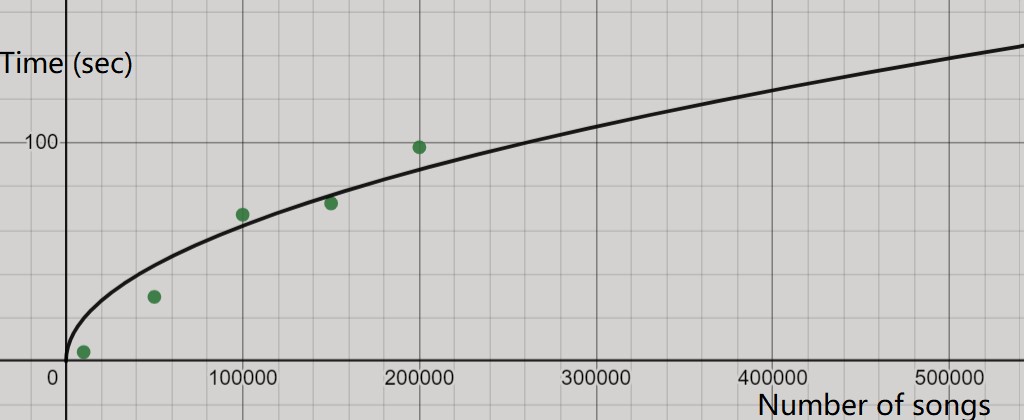
One issue encountered was to achieve a balance between amount of data and the time that the program spends running. A larger dataset means that the recommendation would be more accurate; however, it would also take a lot of time. For example, using the current program, this line of code, song_df = song_df.head(10000) only considers the first 10000 songs in the dataset. Using 10000 songs, the program takes about 4.21 seconds to run:
# record time
startTime = time.time()
init(["Hey_ Soul Sister"])
print("Total time elapsed: " + str(time.time() - startTime))
Whereas increasing the program to use 50000 songs takes about 29.51 seconds. 100000 songs takes 67.23 seconds. 150000 songs took 72.41 seconds. 200000 songs took 98.10 seconds. As a result, we could only use a small portion of the dataset even when it had a lot more data (using 10000 songs out of a million songs).
The pictures below demonstrate the precision-recall graph of the program:
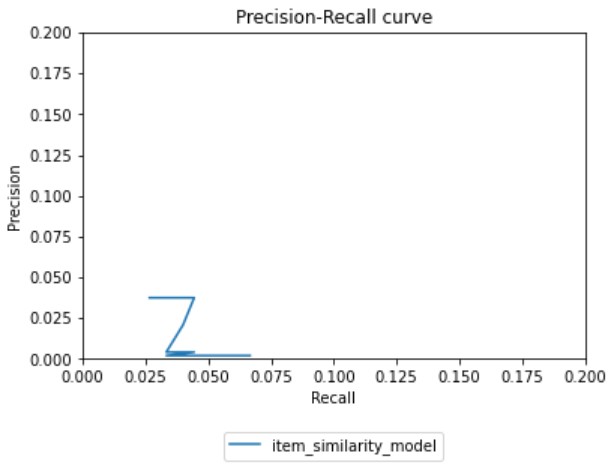
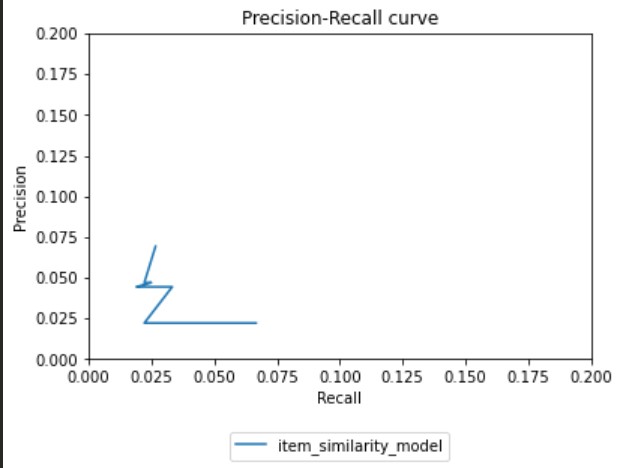
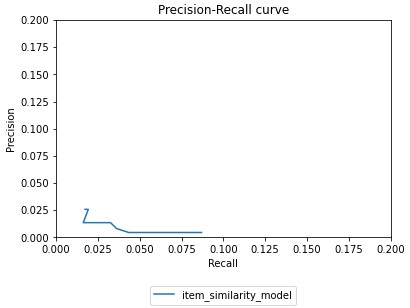
Specifically, precision and recall are utilized in binary classification algorithms. In the case of the music recommender, “binary” refers to whether the recommended song is correct or not.
What the precision-recall program does is that it splits the dataset into training data and testing data. It then finds the same songs found in both data, and selects a random sample from the data. Afterwards, for the training data, the program generates recommendations for each song found in the random sample. For the testing data, the program first locates the user that listened to the song in the sample. The program then finds other songs that the user listened to. This list of songs is used as the “actual” songs that the user likes. The program then compares the number of songs that match between the recommendations and the “actual” songs that the user likes. This number, along with other statistics, such as the length of the testing data, is used to calculate the precision and recall score.
A higher precision is better. The low score of our precision could be because the actual amount of songs that was used in the program was limited due to only selecting 10000 songs. Furthermore, the limitation could be due to the fact that we don’t actually have data about songs the user likes. The best we have is the number of songs that they listened to, and in this project, we assumed that that is the “actual” songs that the user likes.
Another limitation in our project is the dataset that we used. Our dataset came from Million Songs Dataset, which had enough data. However, the songs were pretty old (before 2010), so our program was limited to recommending pretty old songs.
Moving Forward
There are a few solutions that I found through research to the limitations mentioned above. For better accuracy, collaborative filtering can be combined with content based filtering. Content based filtering utilizes information about the user to make recommendations (while collaborative uses other user’s preferences to make recommendations).
An interesting article that I saw suggests alternating least squares as a better recommender system than collaborative filtering.
The article mentions three issues with collaborative filtering, which are the same issues that I found while making the music recommender. They are:
- Item cold-start problem: Items with very little interactions that are used for recommendations are inaccurate
- Scalability issue: Hard to scale with large amounts of data
The reason why I chose to use collaborative filtering was that it was easier to understand given that we had very little knowledge of machine learning before starting the project. Based on research, collaborative filtering is a basic recommendation system, so there are other, better systems (such as alternating least squares). However, collaborative filtering is one of the systems that websites such as Amazon and Netflix use for their recommendations, so it is still a system that is widely used.
The code
The data
The data comes from two datasets: 10000.txt and song_data.csv. 10000.txt contains the user id, song id, and number of times a user listened to a song. song_data.csv consists of the song id, song name (title), album name (release), artist’s name, and year.
The two datasets can be accessed here.
Data cleaning
Throughout the code, there are lines that help filter the data. This is an important step in order to make sure that the data is clean so that the format is consistent throughout the entire file.
-
Line (#):
song_df_2 = song_df_2.drop_duplicates(['song_id'])This removes all duplicate song ids, ensuring that the file with the song info does not contain rows with duplicate songs.
Overview
The main steps in the recommender is listed below. They can be found in the init() function.
- Take the two datasets and combine them into one dataset.
- Take a subset of the dataset (ex: 10000 songs).
- Make an item similarity recommender a. Obtain unique songs from the training data
b. Make a cooccurence matrix from the training data and populate it with similarity scores
c. Take the highest scores from the cooccurence matrix, locate the songs they correspond to, and output those songs
Common variables
The code is quite long, so below are definitions of the commonly used variables in this program. These can be used to refer back to if you’re not sure what a certain variable stands for.
-
input_song: A list of songs that the user inputs. These are the songs that the user likes and wants to get recommendations for. -
all_songs: A list of unique values in the training data under thesongcolumn.
init
def init(input_song):
# triplets_file consists of a "triplet" of data (user id, song id, listen count)
triplets_file = "data/test2/10000.txt"
songs_metadata_file = 'data/test2/song_data.csv'
# read table and define columns
song_df_1 = pandas.read_table(triplets_file,header=None)
song_df_1.columns = ['user_id', 'song_id', 'listen_count']
# read song metadata
song_df_2 = pandas.read_csv(songs_metadata_file)
# clean data to remove rows with duplicate songs
song_df_2 = song_df_2.drop_duplicates(['song_id'])
# merge the two dataframes above to create input dataframe for recommender systems
# keep the triplet data's song id, drop the duplicate column of "song_id" in the song data's file
song_df = pandas.merge(song_df_1, song_df_2, on="song_id", how="left")
# subset consists of first 10000 songs
song_df = song_df.head(10000)
song_df['song'] = song_df['title'].map(str)
# alternatively, you can:
# merge song title and artist_name columns to make a merged column
# because this recommender only recommends songs; we don't need artists
#song_df['song'] = song_df['title'].map(str) + " - " + song_df['artist_name']
# using scikit-learn to split data into training and testing data
# test_size = 0.20: Testing size is 20% => training size is 80%
train_data, test_data = train_test_split(song_df, test_size = 0.20, random_state=0)
# make an item similarity recommender
is_model = item_similarity_recommender_py(train_data, "user_id", "song")
# predict what song you would like based on a song that you input
df = is_model.get_similar_items(input_song)
return df
10000.txt is read by Pandas into a dataframe, and assigned columns consisting of a user id, song id, and listen count. song_data.csv is also read by Pandas into a dataframe.
The next step is to combine the two datasets. However, notice how both 10000.txt and song_data.csv includes the song id? If the two datasets were combined, they would have duplicate entries. Therefore, they merge on the song_id column, while keeping the first dataset’s song_id column.
The dataframe is then limited to the first 10000 songs. This number can be adjusted to be larger, which would probably provide more accurate results. However, this comes at the expense of taking more time to run the program.
Afterwards, the dataset is created with a song column. This column takes information from the title column. This is important because the title of the song is used when the user inputs a song name on the frontend and when the code outputs a song as recommendation.
Alternatively, you can create a song column that consists of the combination of the title column and the artist_name. Therefore, the format of the data when being entered is Song name - Artist name.
# alternatively, you can:
# merge song title and artist_name columns to make a merged column
# because this recommender only recommends songs; we don't need artists
song_df['song'] = song_df['title'].map(str) + " - " + song_df['artist_name']
After that, we want to split the dataset into testing and training data.
train_data, test_data = train_test_split(song_df, test_size = 0.20, random_state=0)
The testing and training data is useful for creating a precision-recall curve to determine the accuracy of the machine learning model.
This uses the scikit-learn library. In this case, the testing data’s size is 20% of the dataset, while the remaining 80% is the training data.
Next, the init() function creates an item similarity recommender using the training data. Finally, the program finds similar songs to the song that the user inputs.
Constructor
is_model = item_similarity_recommender_py(train_data, "user_id", "song")
def __init__(self, train_data, user_id, item_id):
self.train_data = train_data
self.user_id = user_id
self.item_id = item_id
Since the code uses OOP, the class is called and the following variables are initialized:
-
The training data (
train_data). -
In addition,
user_idis assigned to the string “user_id”, anditem_idis assigned to the string “song”. Therefore, in this case, it is important to note that the item is the song (which makes sense because the recommendation really focuses on the user and their ratings for the songs).
get_similar_items(input_song)
The next piece of code passes in a list of songs that the user inputs:
df = is_model.get_similar_items(songList)
# Get similar songs to those that the user inputs
def get_similar_items(self, input_song):
# Obtain unique songs in the training data
all_songs = self.get_all_items_train_data()
print("no. of unique songs in the training set: %d" % len(all_songs))
# Make a cooccurence matrix
cooccurence_matrix = self.construct_cooccurence_matrix(input_song, all_songs)
# Use cooccurence matrix to generate recommendations
user = ""
df_recommendations = self.generate_top_recommendations(user, cooccurence_matrix, all_songs, input_song)
return df_recommendations
get_all_items_train_data() is a function that returns a list of unique values in the training data under the song column. In other words, the function returns a list of unique songs in the training data.
Next, a cooccurrence matrix is created, which is then used to generate the recommendations.
construct_cooccurence_matrix(input_song, all_songs)
# Make a coocurrence matrix
def construct_cooccurence_matrix(self, input_song, all_songs):
# Obtain the user IDs of those who ranked songs that are the same as the songs that the user inputted
user_songs_users = []
for i in range(len(input_song)):
user_songs_users.append(self.get_item_users(input_song[i]))
# Make a cooccurence matrix
cooccurence_matrix = np.matrix(np.zeros(shape=(len(input_song), len(all_songs))), float)
# Calculate similarity
for i in range(len(all_songs)):
# Obtain a set of unique user IDs of those who listened to a song (song refers to the list of unique values in the training data under the song column)
songs_i_data = self.train_data[self.train_data[self.item_id] == all_songs[i]]
users_i = set(songs_i_data[self.user_id].unique())
for j in range(len(input_song)):
# Take a user ID from user_songs_users
users_j = user_songs_users[j]
# Compare the user ID from user_songs_users with the user IDs in the set
users_intersection = users_i.intersection(users_j)
if len(users_intersection) != 0:
# Find the union of the two user IDs
users_union = users_i.union(users_j)
cooccurence_matrix[j,i] = float(len(users_intersection))/float(len(users_union))
else:
cooccurence_matrix[j,i] = 0
return cooccurence_matrix
The program looks at the values under the song column in the training data. It first finds the values that match the songs that the user inputted (found in input_song). Then, the program adds the IDs of the users who ranked the songs into a list called user_songs_users.
Afterwards, a cooccurence matrix is created using numpy. The matrix originally consists of all zeros, and has a number of rows that is equal to the number of songs in input_song, and a number of columns that is equal to the number of songs in all_songs (a list of unique values in the training data under the song column).
Afterwards, we want to calculate simlarity by obtaining a set of unique user IDs of those who listened to a song and comparing it with the user IDs of those who listened to the songs that the user inputs.
Specifically, the code that calculates similarity does the following through iteration:
-
It finds the rows in the dataset where the values under the
songcolumn in the training data match the name of a song inall_songs(the name depends on the value ofiin the for loop, which determines the index ofall_songs). -
A set of unique user IDs are obtained from the rows in step 1.
-
The program uses a nested for loop for more iteration:
a. The code takes a user ID from user_songs_users and compares it with the user IDs in the set from step 2 (finding the intersection).
b. If there is a match, the union of the two user IDs from step 3a are recorded.
c. The quotient of the length of the intersection and the length of the union are added into the cooccurence matrix.
generate_top_recommendations()
# Use cooccurence matrix to generate recommendations
def generate_top_recommendations(self, user, cooccurence_matrix, all_songs, input_song):
print("Non zero values in cooccurence_matrix :%d" % np.count_nonzero(cooccurence_matrix))
# Calculate a recommendation score
user_sim_scores = cooccurence_matrix.sum(axis=0)/float(cooccurence_matrix.shape[0])
user_sim_scores = np.array(user_sim_scores)[0].tolist()
# Sort the scores from highest to lowest
sort_index = sorted(((e,i) for i,e in enumerate(list(user_sim_scores))), reverse=True)
# Make a new dataframe
columns = ['user_id', 'song', 'score', 'rank']
df = pandas.DataFrame(columns=columns)
# Add top 10 highest scores to dataframe
rank = 1
print(sort_index)
for i in range(len(sort_index)):
if ~np.isnan(sort_index[i][0]) and all_songs[sort_index[i][1]] not in input_song and rank <= 10:
df.loc[len(df)]=[user,all_songs[sort_index[i][1]],sort_index[i][0],rank]
rank += 1
# Error checking
if df.shape[0] == 0:
print("The current user has no songs for training the item similarity based recommendation model.")
return -1
else:
return df
Using the cooccurence matrix, the recommendation score is calculated by dividing the sum of the values in each column with the number of rows. These scores are then converted to a list.
Using this list of scores, a new list is created that sorts the scores from highest to lowest and includes their corresponding index.
A new dataframe is then created that contains the user id, song, score, and rank.
The code then loops through the sorted list of scores and checks if the top values actually has a score and if these values are different from the song that the user inputs. Lastly, the dataframe adds in the name of the song (using the index in sort_index and locating it in all_songs), and its score.